数据结构:配对堆
配对堆是一个支持插入,查询/删除最小值,合并,修改元素等操作的数据结构,是一种可并堆。有速度快和结构简单的优势,但由于其为基于势能分析的均摊复杂度,无法可持久化。
配对堆是一个支持插入,查询/删除最小值,合并,修改元素等操作的数据结构,是一种可并堆。有速度快和结构简单的优势,但由于其为基于势能分析的均摊复杂度,无法可持久化。
从二叉堆的结构说起,它是一棵二叉树,并且是完全二叉树,每个结点中存有一个元素(或者说,有个权值)。
堆性质:父亲的权值不小于儿子的权值(大根堆)。同样的,我们可以定义小根堆。本文以大根堆为例。
由堆性质,树根存的是最大值(getmax 操作就解决了)。
堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值。
每个节点的键值都大于等于其父亲键值的堆叫做小根堆,否则叫做大根堆。STL 中的 priority_queue 其实就是一个大根堆。
(小根)堆主要支持的操作有:插入一个数、查询最小值、删除最小值、合并两个堆、减小一个元素的值。
一些功能强大的堆(可并堆)还能(高效地)支持 merge 等操作。
一些功能更强大的堆还支持可持久化,也就是对任意历史版本进行查询或者操作,产生新的版本。
操作 \ 数据结构 |
配对堆 | 二叉堆 | 左偏树 | 二项堆 | 斐波那契堆 |
|---|---|---|---|---|---|
| 插入(insert) | |||||
| 查询最小值(find-min) | |||||
| 删除最小值(delete-min) | |||||
| 合并 (merge) | |||||
| 减小一个元素的值 (decrease-key) | |||||
| 是否支持可持久化 |
表格来自于Wikipedia
习惯上,不加限定提到「堆」时往往都指二叉堆。
本篇博客通过数据分布的角度引入降维的思路,并围绕PCA讨论降维的几种方法。
我们知道,解决过拟合的问题除了正则化和添加数据之外,降维就是最好的方法。降维的思路来源于维度灾难的问题,我们知道
这就是所谓的维度灾难,在高维数据中,主要样本都分布在立方体的边缘,所以数据集更加稀疏。
降维的算法分为:
上一篇博客讲解了并查集,但是没有给出具体的复杂度分析,这里开另外一个页面专门介绍。
本部分内容较大程度上参考并修改了 时间复杂度 - 势能分析浅谈
本篇博客引入并介绍了几种线性分类模型。
对于分类任务,线性回归模型就无能为力了,但是我们可以在线性模型的函数进行后再加入一层激活函数,这个函数是非线性的,激活函数的反函数叫做链接函数。我们有两种线性分类的方式:
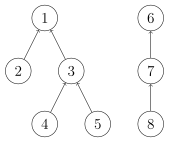
并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素。
顾名思义,并查集支持两种操作:
并查集在经过修改后可以支持单个元素的删除、移动;使用动态开点线段树还可以实现可持久化并查集。
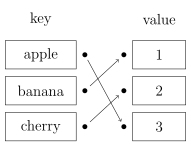
哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。所谓以「key-value」形式存储数据,是指任意的键值 key 都唯一对应到内存中的某个位置。只需要输入查找的键值,就可以快速地找到其对应的 value。可以把哈希表理解为一种高级的数组,这种数组的下标可以是很大的整数,浮点数,字符串甚至结构体。
本篇博客介绍了最简单的一种机器学习模型——线性回归,主要包含以下内容:
链表是一种用于存储数据的数据结构,通过如链条一般的指针来连接元素。它的特点是插入与删除数据十分方便,但寻找与读取数据的表现欠佳。