ViLT论文阅读笔记:ViLT:Vision-and-Language Transformer Without Convolution or Region Supervision
原文链接:https://arxiv.org/abs/2102.03334 作者单位:Kakao Enterprise、Kakao Brain、NAVER AI Lab 会议:ICML 2021
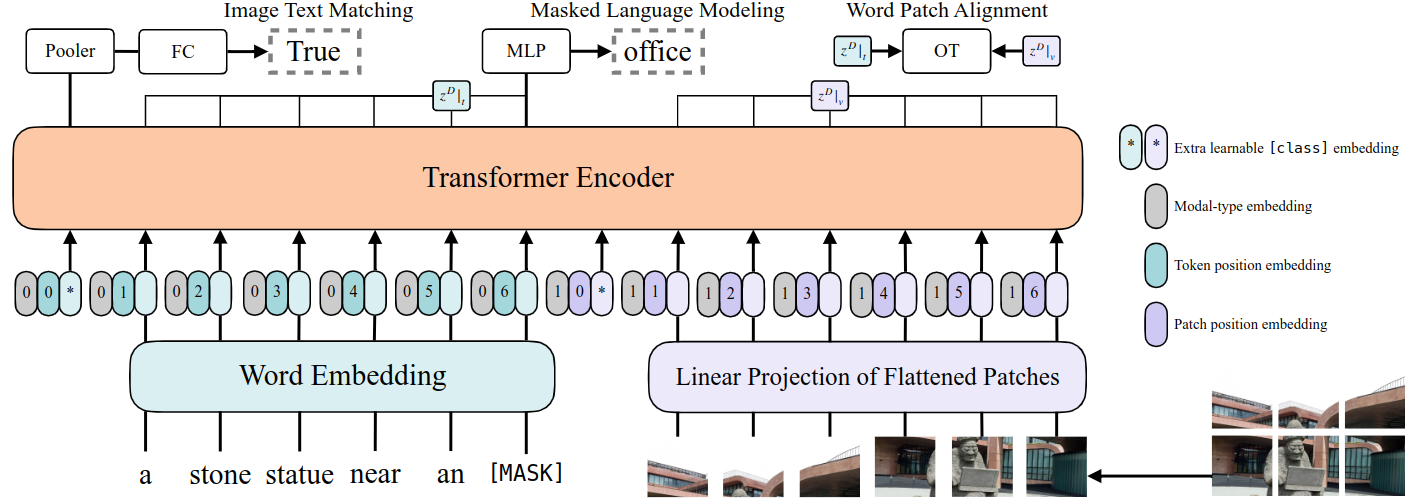
原文链接:https://arxiv.org/abs/2102.03334 作者单位:Kakao Enterprise、Kakao Brain、NAVER AI Lab 会议:ICML 2021
本项目实现了 DETR(DEtection TRansformer)模型的一个简化版本,并最终发布在了 GitHub 上:MiniDETR 项目地址。
这是一个目标检测模型的完整训练框架。
本篇博客总结了我对 DETR 的理解、模型的核心模块、关键实现细节、训练调优策略,以及一些工程实践经验。
论文链接:arXiv:2005.12872v3 作者:Nicolas Carion et al. (Facebook AI Research) 模型关键词:Set Prediction、Hungarian Matching、Transformer、Object Queries
这篇论文提出了一个极具颠覆性的目标检测框架 —— DETR(DEtection TRansformer),它摒弃了 anchor、NMS、候选框等传统组件,使用纯粹的 CNN + Transformer 结构进行端到端训练,实现了“无组件”目标检测。
本项目是对论文 "Learning Transferable Visual Models From Natural Language Supervision"(CLIP) 的一次轻量实现,适用于资源受限环境(如单卡 8GB 显存)。该实现完整复现了 CLIP 的核心思想与训练流程,并使用 Flickr8k 数据集进行实验验证。
论文标题:Learning Transferable Visual Models From Natural Language Supervision 作者单位:OpenAI 会议:ICML 2021
论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
作者:Colin Raffel et al. (Google Research)
链接:arXiv:1910.10683
本项目为我在学习 Vision Transformer(ViT)架构时的工程实践记录。目标是从零实现一个简化版的 ViT 模型,并在 CIFAR-10 上进行训练与推理。完整代码已上传至 GitHub:
🔗 https://github.com/QianQing26/MiniViT
论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 论文链接:arXiv:2010.11929
本文是我在精读 BERT 论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》时,遇到的两个重要但难以理解的问题。虽然论文中只用几行文字描述,但通过查阅资料和向GPT请教,我终于理解了背后的逻辑。在这里记录下来,方便自己日后获得启发。
这是一篇我的学习记录,阅读了 Google 于 2018 年提出的经典工作 —— BERT(Bidirectional Encoder Representations from Transformers)的论文。