FLAVA论文阅读笔记:FLAVA: A Foundational Language And Vision Alignment Model
论文标题: FLAVA: A Foundational Language And Vision Alignment Model
作者: Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, et al.
论文链接: arXiv:2112.04482
1. 为什么提出FLAVA?
当前多模态预训练模型存在两种主流:
- 对比式双编码器(CLIP/ALIGN)
- 模态分开训练 → 适合检索(图文对齐)
- 缺点:无法处理复杂融合任务(如VQA)
- 模态分开训练 → 适合检索(图文对齐)
- 融合式单编码器(UNITER/ViLT)
- 模态融合 → 擅长推理
- 缺点:难以泛化到单模态任务
- 模态融合 → 擅长推理
FLAVA 的目标是构建一个真正意义上的“通用基础多模态模型”,能够同时支持: - 单模态视觉任务(如图像分类) - 单模态语言任务(如情感分类) - 跨模态任务(如VQA、图文检索)
它使用统一的 Transformer 结构训练三个子编码器,使模型既能解耦又能融合,成为“语言-视觉齐头并进”的基础模型。
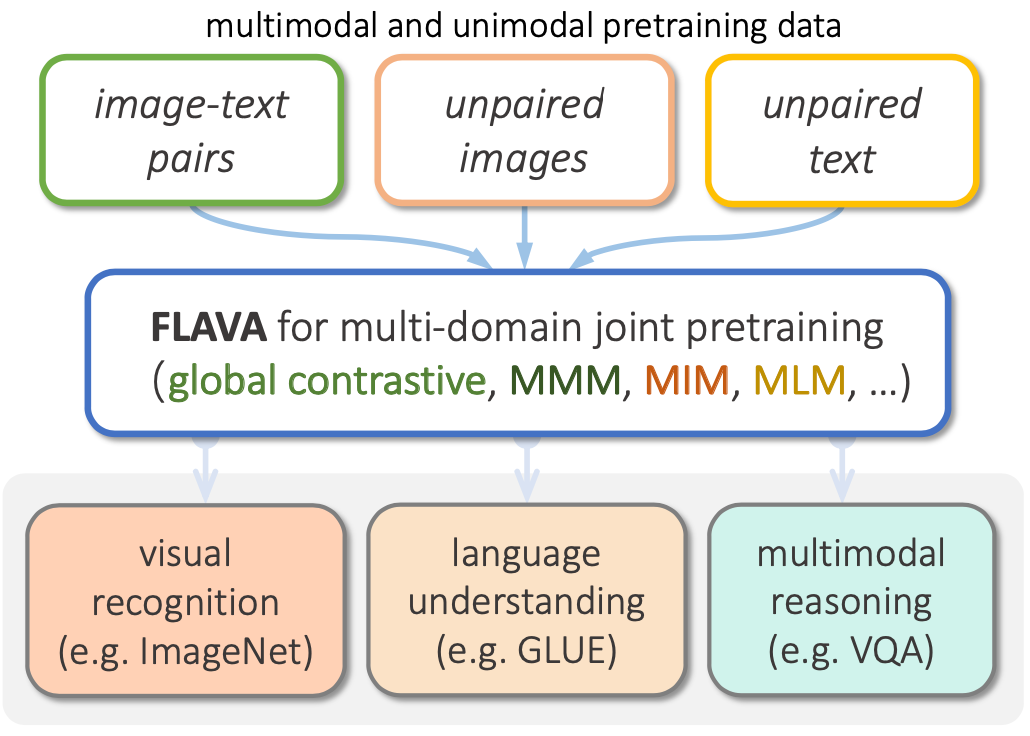
2. 模型结构总览
FLAVA 架构包含三大模块,均基于 ViT 构建:
| 编码器模块 | 输入内容 | 输出 [CLS] Token | 用于任务 |
|---|---|---|---|
| Image Encoder | 图像 patch | [CLS_I] |
图像分类、对比学习 |
| Text Encoder | 文本 tokens | [CLS_T] |
文本分类、对比学习 |
| Multimodal Encoder | [hI] + [hT] |
[CLS_M] |
多模态推理类任务 |
各模块使用标准 Transformer(MHA + FFN + 残差 + LN),仅嵌入方式不同。
3. 预训练目标与策略
3.1 单模态目标
用于提升图像/文本各自的表示学习能力:
- Masked Image Modeling (MIM):图像版的BERT
- 输入:mask部分patch
- 输出:预测dVAE token(类似BEiT)
- 损失函数:交叉熵
- 输入:mask部分patch
- Masked Language Modeling (MLM):文本mask预测
- 15% BERT-style masking
- 输出:预测token ID
- 损失函数:交叉熵
- 15% BERT-style masking
3.2 多模态目标
用于学习图文间的对齐、融合与生成:
(1)图文对比损失:Global Contrastive Loss
- 输入:图像+文本对
- 输出:两个 [CLS] 向量
- 损失函数:
与 CLIP 相同,鼓励图文对应对齐。
(2)图文匹配任务:Image-Text Matching (ITM)
- 使用 Multimodal Encoder 的
[CLS_M]→ 过MLP → 输出是否配对
(3)掩码多模态建模:Masked Multimodal Modeling (MMM)
- 同时 mask 图像 patch 和文本 token
- Multimodal Encoder 进行联合预测
4. 模块激活策略:Round-Robin
在训练过程中,FLAVA 采用 Round-Robin Sampling:
- 每个step只选择一种数据类型:
- image-only → 训练 MIM,激活 image encoder
- text-only → 训练 MLM,激活 text encoder
- image-text pair → 训练 MMM / ITM / GC,激活所有模块
优点: - 显存节省 - 稳定优化 - 三类任务均衡训练
5. 下游任务适配方式
FLAVA 可以灵活用于三类任务:
| 下游任务类型 | 编码器模块 | [CLS] 用法 | 任务头 |
|---|---|---|---|
| 图像任务 | Image Encoder | [CLS_I] |
Linear Head |
| 文本任务 | Text Encoder | [CLS_T] |
Linear Head |
| 多模态任务 | All + Multimodal | [CLS_M] |
分类 / 推理头 |
6. 实验结果亮点
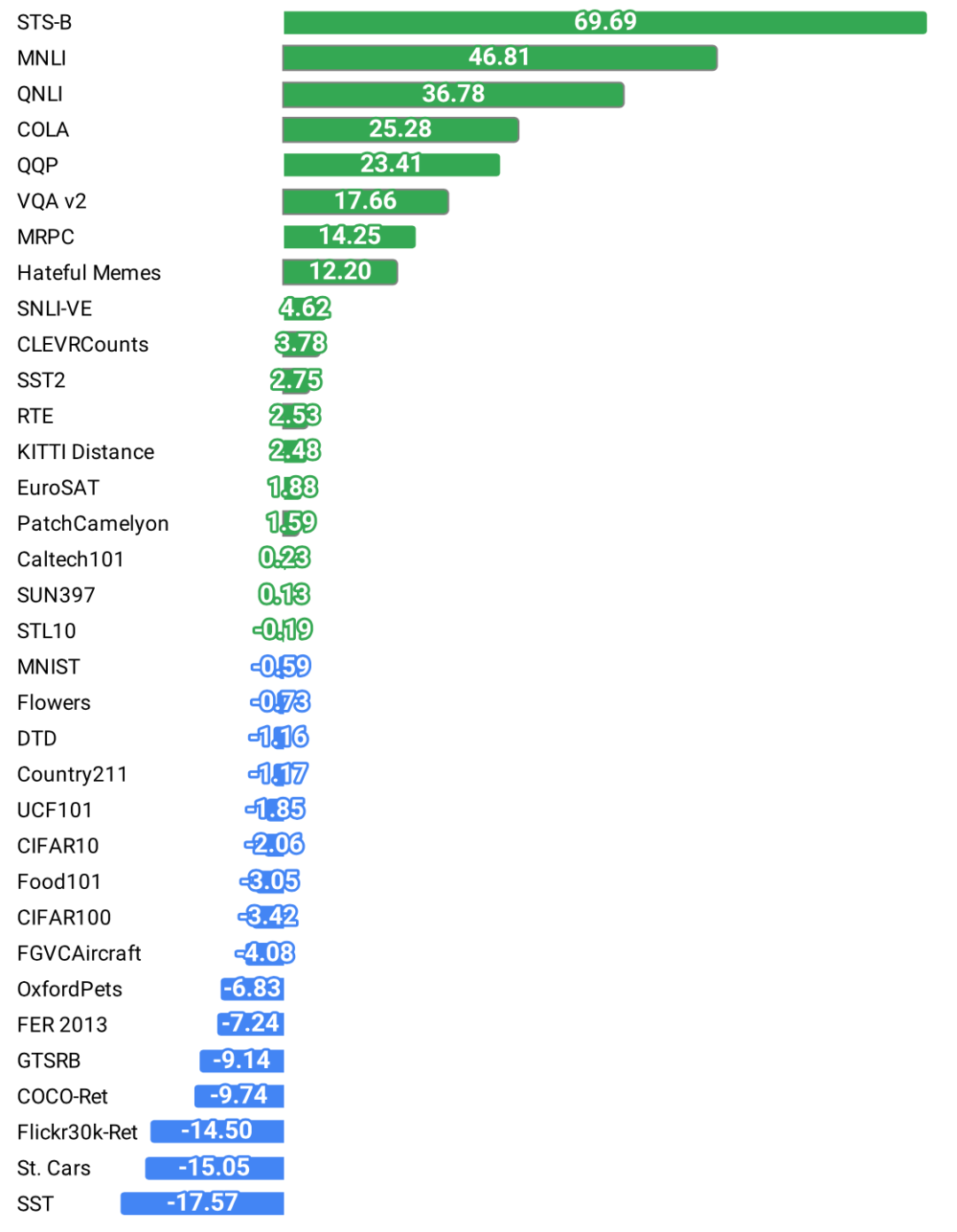
- 在 35 个 benchmark 任务 上进行评估,涵盖图像、文本、多模态任务
- 超越CLIP 在图文融合类任务上的表现(VQA、Hateful Memes等)
- 即使只用 ImageNet-1k 作为图像数据,也能达到较好视觉结果
- 文本任务上可媲美 RoBERTa-base
7. 我的理解与总结
FLAVA 是我学习多模态视觉语言模型的重要起点,它统一了对比学习和融合学习两种范式,采用模块化结构,既能灵活适配不同任务,又具备基础模型的可扩展性。
我特别喜欢它的几点设计:
- 三编码器结构清晰,解耦明确;
- Round-Robin 模态调度策略值得借鉴;
- 模块化训练 + 模块化使用,便于工程部署