BLIP论文阅读笔记:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
论文标题: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 作者: Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi (Salesforce Research) 论文链接: arXiv:2201.12086
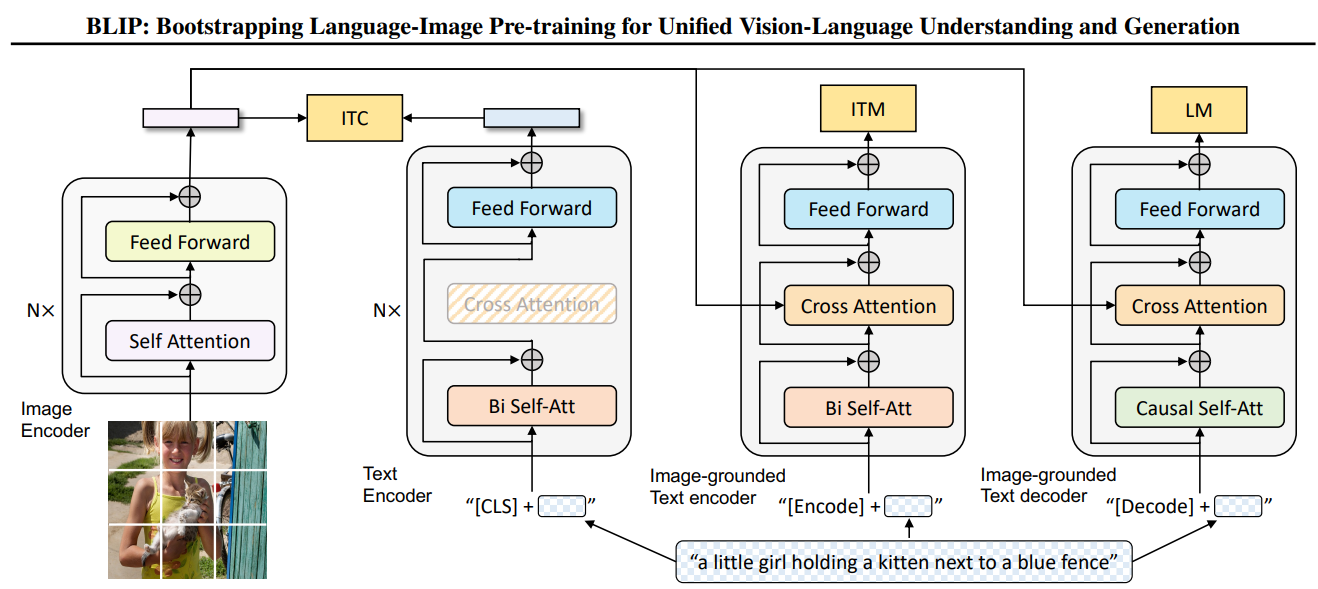
1. 为什么提出BLIP?
当前Vision-Language Pre-training (VLP)方法存在两类主要问题:
- 模型问题:
- Encoder-only模型(如CLIP、ALBEF)在理解任务上强,但难以直接迁移到生成任务。
- Encoder-Decoder模型(如SimVLM)适合生成任务,却在检索等理解任务上表现不足。
- 数据问题:
- 大多数VLP依赖web爬取的图文对,这些alt-text噪声大、信息不足。
BLIP的目标:
- 构建统一模型,兼顾理解任务与生成任务。
- 在无需大幅增加人工标注的情况下,通过自动处理,让海量web数据更干净、更有信息量。
2. 模型结构:MED (Multimodal Mixture of Encoder-Decoder)
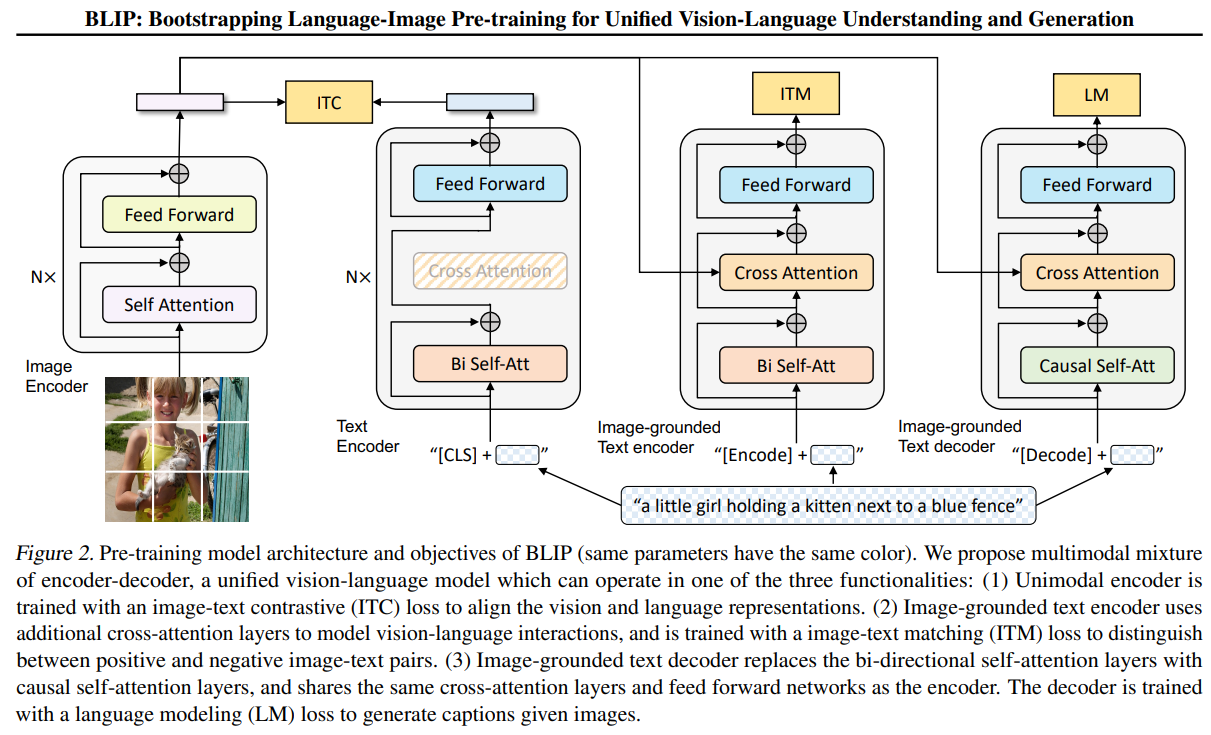
BLIP提出MED架构,是一个统一的多模态Transformer架构,一个能使用同一套参数在不同任务下切换模式的统一模型:
- Unimodal Encoder: 用于Image-Text Contrastive (ITC)任务,分别编码图像和文本,对齐特征空间。
- Image-grounded Text Encoder: 在文本Transformer中插入cross-attention,做Image-Text Matching (ITM)。
- Image-grounded Text Decoder: 将双向自注意力改为因果自注意力,结合cross-attention生成文本(Language Modeling, LM)。
特点:
- 一套Transformer参数共享,根据任务切换mask和结构。
- ViT作为图像编码器,BERT结构作为文本基底。
- 高效性:减少参数冗余,多任务共享学习。
Mixture的含义:
- 一套Transformer → 三种前向路径 → 不同mask/不同special tokens/是否开启cross-attention → 实现理解+生成任务统一。
结构细节与实现组件
(1) 图像编码器
- ViT结构:Patch embedding → Transformer →
[CLS]特征 + Patch特征 - 输出:
[CLS]→ 图像全局特征- Patch特征序列 → 提供给Cross-Attention
代码框架示例:
1 | class ImageEncoder(nn.Module): |
(2) Text Transformer
必须支持:
- 参数共享:embedding、transformer blocks统一
- Self-Attention类型切换:
- Encoder模式 → 双向mask
- Decoder模式 → 因果mask
- Cross-Attention可选:ITC不启用,ITM/LM启用
- 特殊token机制:
[CLS]用于ITC全局特征[ENC]用于ITM分类[DEC]用于LM生成起始点
伪代码:
1 | class MEDTransformerBlock(nn.Module): |
(3) 三种模式对应特征
| 模式 | Text起始token | Self-Attention | Cross-Attention | 输出 |
|---|---|---|---|---|
| ITC | [CLS] |
Bi-SA | ✗ | [CLS] embedding → contrastive head |
| ITM | [ENC] |
Bi-SA | ✓ | [ENC] embedding → classifier |
| LM | [DEC] |
Causal-SA | ✓ | token概率分布 |
一些细节
- forward时根据token判断模式(而不是写三份模型)。
- mask逻辑必须动态生成,保证Encoder与Decoder共享block。
- 同一batch支持多任务样本 → 输入序列混合
[CLS]/[ENC]/[DEC],loss分支根据起始token决定。 - 图像特征缓存:同一图像在ITC、ITM、LM三个loss中共用一次ViT输出,节省计算。
3. 数据方法:CapFilt
VLP面对的一个数据瓶颈是:
- 大量来自Web的图文对(image-text pairs)质量低:文本经常只是文件名、短标签或者与图像内容无关。
- 如果直接拿这些噪声数据去做预训练,模型的对齐能力(ITC、ITM)会受到严重影响。
所以作者希望:
- 不依赖大量人工标注,也能自动生成更干净、更丰富、更有信息量的训练数据。
BLIP在数据层面的核心创新是Captioning + Filtering (CapFilt):

CapFilt是 “Captioning + Filtering” 的缩写,它不是单一步骤,而是一个两阶段的数据自举(bootstrapping)策略:
- Captioning (Cap):生成更优质的文本描述
- 用一个初始的Captioner模型(由BLIP MED结构fine-tune得到)给web图片生成新的caption(synthetic caption)。
- 生成策略使用 nucleus sampling(top-p采样,p=0.9),不是beam search。
- 原因:nucleus sampling生成的句子更有多样性 → 更好的泛化性,即便包含少量噪声,也比“安全但重复”的beam search强。
- Filtering (Filt):过滤无关或低质量文本
- 用一个Filter模型(也是BLIP结构fine-tune得到),计算image-text对的匹配分数 (ITM score)。
- 根据阈值筛掉不相关的web原始文本和生成的synthetic captions。

它们不是直接在噪声web数据上训练的。
- 它们先由已经预训练好的BLIP模型参数初始化。
- 然后用COCO等人工标注的高质量数据做轻量微调:
- Captioner:在COCO caption任务上fine-tune → 学习生成高质量描述。
- Filter:在COCO ITM任务上fine-tune → 学习判断图像与文本是否匹配。
这样保证了初始Captioner和Filter的质量足够高,不会完全被web噪声带偏。
最终得到:
1 | Bootstrapped Dataset = |
特点:
- 数量:比COCO大得多,比原始web数据更干净。
- 质量:既有人工标注的准确性,又有synthetic captions带来的多样性。
用这个新的数据集去重新预训练BLIP主模型,性能显著提升。

4. 预训练目标
BLIP联合优化三个loss:
- ITC (Image-Text Contrastive Loss) → 对齐视觉和语言特征空间。
- ITM (Image-Text Matching Loss) → 学习细粒度匹配关系。
- LM (Language Modeling Loss) → 生成文本,提高跨模态生成能力。
(1) Image-Text Contrastive Loss (ITC)
激活的模型部分如下:
- Image Encoder (ViT) → 提取图像特征
- Text Encoder (Bi-directional Transformer) → 提取文本特征
- 不涉及cross-attention,不生成文本。
假设batch大小为
- 图像→文本方向的对比损失:
- 文本→图像方向类似,最终ITC loss为二者平均。
(2) Image-Text Matching Loss (ITM)
激活的模型部分如下:
- Image Encoder + Image-grounded Text Encoder
- 在文本encoder内部增加 Cross-Attention (CA),让文本特征能直接融合视觉特征。
- 输出的[Encode] token经过一个 线性分类头,预测该对是否匹配。
这是一个二分类任务,损失如下:
(3) Language Modeling Loss (LM)
激活的模型部分如下:
- Image Encoder + Image-grounded Text Decoder
- Text Decoder与Encoder共享embedding、cross-attention、FFN层,只是:
- 自注意力从双向(Bi-SA)换成因果(Causal-SA),保证自回归生成。
采用标准的自回归交叉熵
(4) 三个Loss联合训练
一次训练的forward pass:
- Image Encoder:图像只计算一次特征。
- Text Transformer:同一组权重执行三次forward(不同mask/模式),得到:
- ITC分支
- ITM分支
- LM分支
总损失:
5. 实验结果
- 在检索、图像描述、VQA、NLVR2、VisDial等任务上均取得SOTA。
- 使用CapFilt + ViT-B (129M数据) 就能超越SimVLM (1.8B数据),说明数据质量 > 数据量。
- Zero-shot迁移到视频-语言任务也有很强表现。
6. 我的理解
- MED的核心点:用一套共享Transformer结构,通过mask策略实现encoder/decoder切换,提高了参数效率与任务统一性。
- CapFilt的价值:先用少量高质量数据训练一个“会说话、会判断”的模型,再让它生成和筛选大量web数据,形成自举循环。
- 设计哲学:不仅在模型上创新,更重视数据端优化,这是BLIP相比于单纯“堆数据/堆参数”的方法更有意思的地方。