ViLT论文阅读笔记:ViLT:Vision-and-Language Transformer Without Convolution or Region Supervision
原文链接:https://arxiv.org/abs/2102.03334 作者单位:Kakao Enterprise、Kakao Brain、NAVER AI Lab 会议:ICML 2021
一、研究背景与动机
视觉-语言预训练模型(Vision-and-Language Pre-training,简称VLP)近年来在VQA、图文检索、NLVR等任务上广泛应用。现有主流方法如UNITER、ViLBERT等,普遍采用重型视觉编码器(如Faster R-CNN)来提取区域特征,配合Transformer实现多模态融合。这种方法虽有效,但也存在几个问题:
- 视觉编码过程开销大,常比Transformer模块本身更耗时;
- 严重依赖区域监督(如VG数据集上的检测器);
- 预定义的视觉词表限制表达能力。
针对这些问题,ViLT 提出了一个极简的视觉-语言Transformer框架,完全去除卷积网络与区域特征,仅依赖图像patch投影即可完成视觉编码。
二、ViLT方法介绍
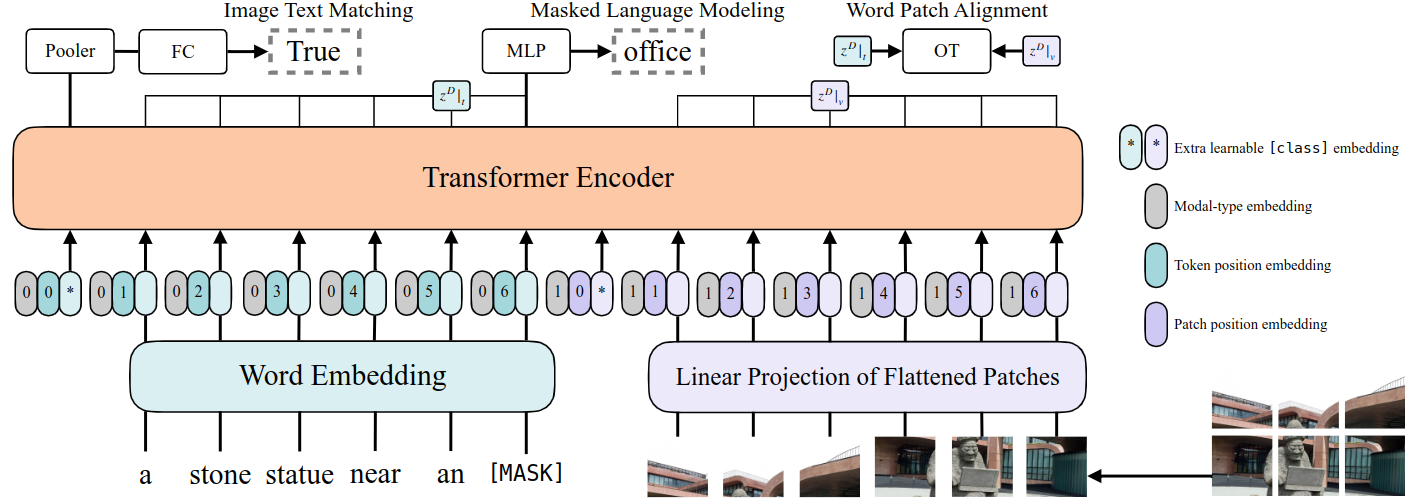
2.1 整体结构
ViLT(Vision-and-Language Transformer)基于一个极简思路:将图像和文本输入都转为序列后,通过同一个Transformer处理。整体结构包括:
- 图像处理:输入图像按 32×32 大小划分为若干patch,每个patch展平成向量后,使用一个线性层进行投影,作为视觉token;
- 文本处理:采用与BERT一致的token embedding,包括词嵌入、位置嵌入;
- 模态融合:图像和文本的token拼接后送入一个标准的Transformer Encoder;
- 任务头:对于图文匹配等任务,使用一个池化后的向量接MLP输出结果。
这种设计与ViT类似,视觉编码仅需线性投影,无需CNN和检测器,大大简化了流程。
2.2 预训练目标
ViLT使用了两个经典的VLP预训练任务:
- Image-Text Matching (ITM):判断一对图文是否匹配;
- Masked Language Modeling (MLM):遮盖部分词语后预测其原始内容。
此外还加入了一个可选任务:
- Word-Patch Alignment (WPA):基于最优传输的方式度量词与图像patch之间的对齐质量。
三、四类视觉-语言模型的分类总结
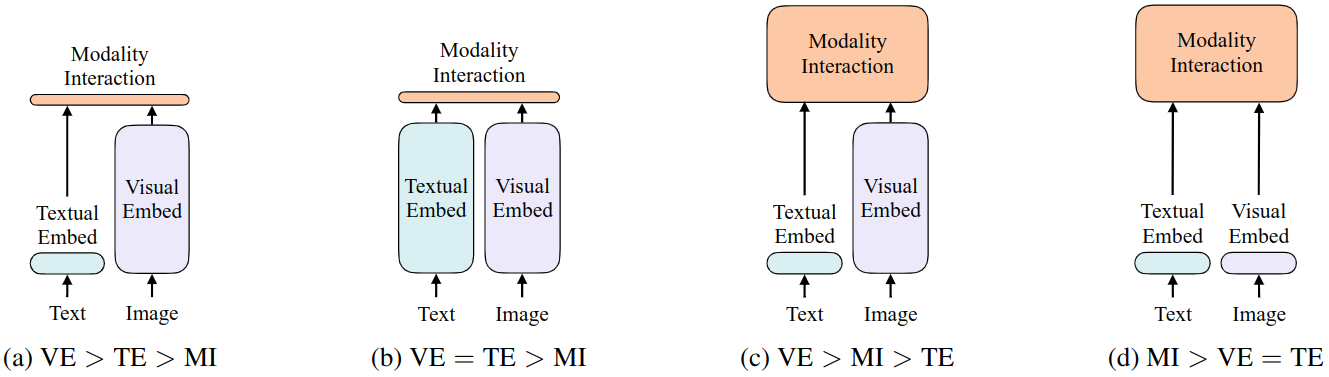
作者在论文中给出了一个有趣的分类框架,将VLP模型分为以下四类(见上图):
- VE > TE > MI(视觉编码开销远大于文本和融合) 代表模型:VSE++, SCAN
- 图文各自用独立encoder,融合层非常浅(如点积)。
- VE = TE > MI(图文编码复杂但融合浅) 代表模型:CLIP
- 图文用并行的Transformer编码,融合阶段只用浅层结构(如点积)。
- VE > MI > TE(视觉编码主导,融合较深) 代表模型:UNITER、ViLBERT
- 使用CNN提取图像特征,图文通过深层Transformer交互。
- MI > VE = TE(融合模块最重) 代表模型:ViLT
- 图文编码都很轻量,几乎所有计算资源用于模态间交互。
ViLT属于第四类模型,是目前唯一一个将Transformer的算力集中用于模态交互的代表。
四、Whole Word Masking(WWM)
ViLT在MLM中引入了Whole Word Masking技术。
背景:
BERT默认的MLM只遮挡子词级别token,而自然语言中的很多信息跨越整个词。
方法:
- 将一个单词中所有组成的子词(wordpiece)一起遮盖;
- 例如,"giraffe"被分成["gi", "##raf", "##fe"],WWM会整体mask掉这三个token;
- 这样,模型不能仅靠语言上下文复原token,而必须利用图像提供的信息。
效果:
WWM显著提高了ViLT在下游任务(如图文检索、NLVR2)上的表现,说明它能有效促进跨模态信息的利用。
五、RandAugment图像增强策略
RandAugment是一种自动化的图像增强方法,先前用于纯视觉任务(如DeiT)。
在ViLT中的使用:
- 在微调阶段(fine-tuning)对图像应用RandAugment;
- 禁用了某些不适合VLP的策略(如颜色反转和cutout);
- 设置增强强度参数 N=2, M=9。
优势:
由于ViLT不依赖于缓存视觉特征,图像在训练阶段可以灵活增强; 而传统VLP模型由于视觉特征提取器是预先提取好的,无法动态增强图像。
效果:
在多个任务中都带来了性能提升,证明了图像增强对视觉-语言模型也有积极影响。
六、实验亮点
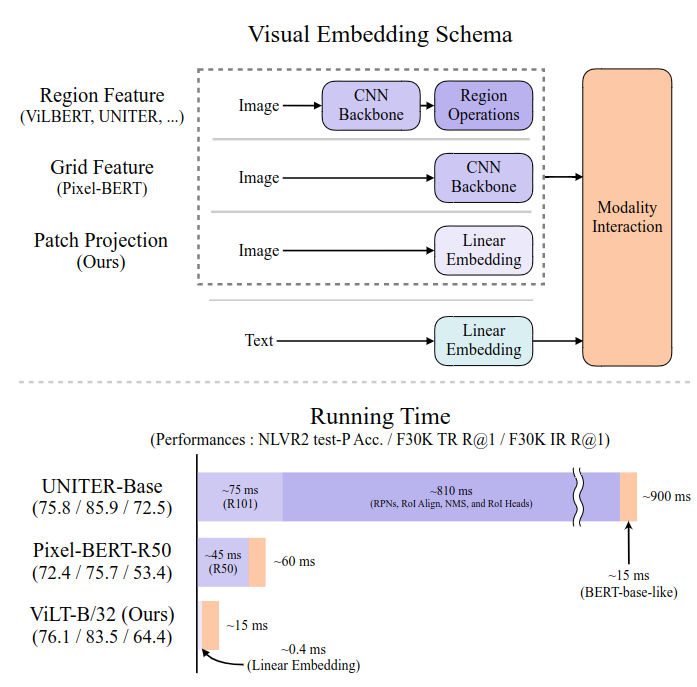
- 在不使用任何检测器和CNN的前提下,ViLT在VQAv2、NLVR2、Flickr30K等任务中性能与主流模型相当甚至更好;
- 推理速度超快:15ms vs 传统模型900ms;
- 参数量和FLOPs更少,部署更友好;
- Zero-shot检索任务中优于ImageBERT等模型。

七、小结
ViLT提出了一个极具启发性的VLP新方向:
- 图像也可以像文本一样“扁平化处理”;
- 强化模态间交互远比堆叠视觉编码器更重要;
- 简化结构≠性能下降,反而让模型具备更强的适应性和推广性。
官方仓库的代码和预训练权重:
GitHub 地址:https://github.com/dandelin/vilt
八、思考与未来工作
论文最后也提出了后续可能探索的方向:
- 更强大的ViLT变体(如ViLT-L、ViLT-H);
- 设计更适合图像patch的masked prediction任务;
- 更复杂的图像增强与文本扰动方法;
- 异模态对齐策略的进一步优化。
在多模态模型逐渐趋向“大模型 + 海量数据”的趋势下,ViLT的极简设计提供了另一个有力的方向:做减法也能做出好模型。