intgetsum(int l, int r, int s, int t, int p){ // [l, r] 为查询区间, [s, t] 为当前节点包含的区间, p 为当前节点的编号 if (l <= s && t <= r) return d[p]; // 当前区间为询问区间的子集时直接返回当前区间的和 int m = s + ((t - s) >> 1), sum = 0; if (l <= m) sum += getsum(l, r, s, m, p * 2); // 如果左儿子代表的区间 [s, m] 与询问区间有交集, 则递归查询左儿子 if (r > m) sum += getsum(l, r, m + 1, t, p * 2 + 1); // 如果右儿子代表的区间 [m + 1, t] 与询问区间有交集, 则递归查询右儿子 return sum; }
voidupdate(int l, int r, int c, int s, int t, int p){ // [l, r] 为修改区间, c 为被修改的元素的变化量, [s, t] 为当前节点包含的区间, p // 为当前节点的编号 if (l <= s && t <= r) { d[p] += (t - s + 1) * c, b[p] += c; return; } // 当前区间为修改区间的子集时直接修改当前节点的值,然后打标记,结束修改 int m = s + ((t - s) >> 1); if (b[p] && s != t) { // 如果当前节点的懒标记非空,则更新当前节点两个子节点的值和懒标记值 d[p * 2] += b[p] * (m - s + 1), d[p * 2 + 1] += b[p] * (t - m); b[p * 2] += b[p], b[p * 2 + 1] += b[p]; // 将标记下传给子节点 b[p] = 0; // 清空当前节点的标记 } if (l <= m) update(l, r, c, s, m, p * 2); if (r > m) update(l, r, c, m + 1, t, p * 2 + 1); d[p] = d[p * 2] + d[p * 2 + 1]; }
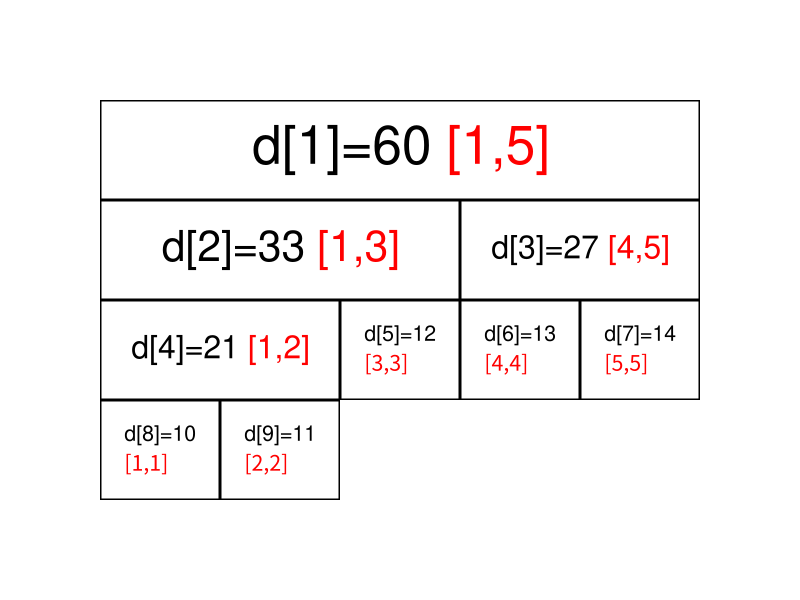
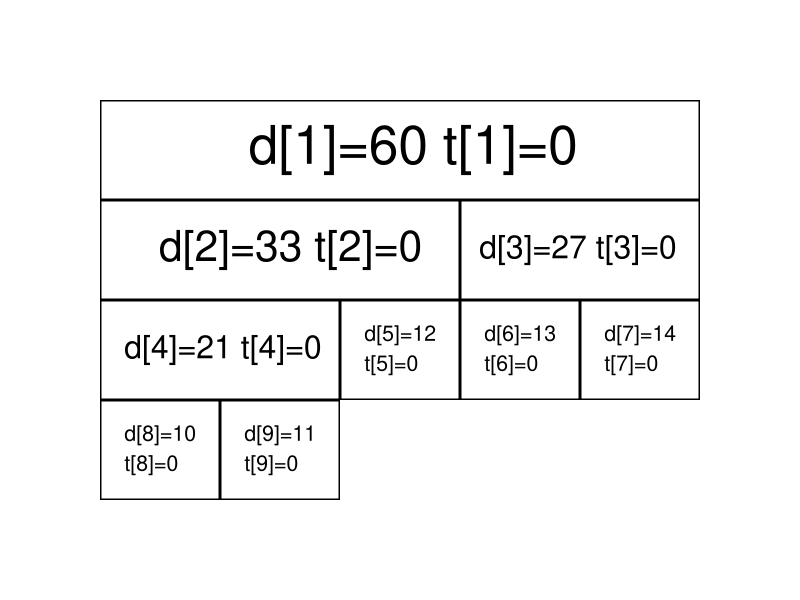
区间查询(区间求和):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intgetsum(int l, int r, int s, int t, int p){ // [l, r] 为查询区间, [s, t] 为当前节点包含的区间, p 为当前节点的编号 if (l <= s && t <= r) return d[p]; // 当前区间为询问区间的子集时直接返回当前区间的和 int m = s + ((t - s) >> 1); if (b[p]) { // 如果当前节点的懒标记非空,则更新当前节点两个子节点的值和懒标记值 d[p * 2] += b[p] * (m - s + 1), d[p * 2 + 1] += b[p] * (t - m); b[p * 2] += b[p], b[p * 2 + 1] += b[p]; // 将标记下传给子节点 b[p] = 0; // 清空当前节点的标记 } int sum = 0; if (l <= m) sum = getsum(l, r, s, m, p * 2); if (r > m) sum += getsum(l, r, m + 1, t, p * 2 + 1); return sum; }
voidupdate(int l, int r, int c, int s, int t, int p){ if (l <= s && t <= r) { d[p] = (t - s + 1) * c, b[p] = c; return; } int m = s + ((t - s) >> 1); // 额外数组储存是否修改值 if (v[p]) { d[p * 2] = b[p] * (m - s + 1), d[p * 2 + 1] = b[p] * (t - m); b[p * 2] = b[p * 2 + 1] = b[p]; v[p * 2] = v[p * 2 + 1] = 1; v[p] = 0; } if (l <= m) update(l, r, c, s, m, p * 2); if (r > m) update(l, r, c, m + 1, t, p * 2 + 1); d[p] = d[p * 2] + d[p * 2 + 1]; }
intgetsum(int l, int r, int s, int t, int p){ if (l <= s && t <= r) return d[p]; int m = s + ((t - s) >> 1); if (v[p]) { d[p * 2] = b[p] * (m - s + 1), d[p * 2 + 1] = b[p] * (t - m); b[p * 2] = b[p * 2 + 1] = b[p]; v[p * 2] = v[p * 2 + 1] = 1; v[p] = 0; } int sum = 0; if (l <= m) sum = getsum(l, r, s, m, p * 2); if (r > m) sum += getsum(l, r, m + 1, t, p * 2 + 1); return sum; }
// root 表示整棵线段树的根结点;cnt 表示当前结点个数 int n, cnt, root; int sum[n * 2], ls[n * 2], rs[n * 2];
// 用法:update(root, 1, n, x, f); 其中 x 为待修改节点的编号 voidupdate(int& p, int s, int t, int x, int f){ // 引用传参 if (!p) p = ++cnt; // 当结点为空时,创建一个新的结点 if (s == t) { sum[p] += f; return; } int m = s + ((t - s) >> 1); if (x <= m) update(ls[p], s, m, x, f); else update(rs[p], m + 1, t, x, f); sum[p] = sum[ls[p]] + sum[rs[p]]; // pushup }
区间询问:
1 2 3 4 5 6 7 8 9
// 用法:query(root, 1, n, l, r); intquery(int p, int s, int t, int l, int r){ if (!p) return0; // 如果结点为空,返回 0 if (s >= l && t <= r) return sum[p]; int m = s + ((t - s) >> 1), ans = 0; if (l <= m) ans += query(ls[p], s, m, l, r); if (r > m) ans += query(rs[p], m + 1, t, l, r); return ans; }