数据结构:并查集
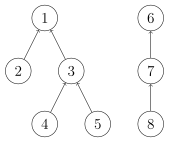
并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素。
顾名思义,并查集支持两种操作:
- 合并(Union):合并两个元素所属集合(合并对应的树)
- 查询(Find):查询某个元素所属集合(查询对应的树的根节点),这可以用于判断两个元素是否属于同一集合
并查集在经过修改后可以支持单个元素的删除、移动;使用动态开点线段树还可以实现可持久化并查集。
Note:并查集不能以较低复杂度实现集合的分离。
初始化
初始时,每个元素都位于一个单独的集合,表示为一棵只有根节点的树。方便起见,我们将根节点的父亲设为自己。
1 | struct dsu { |
查询
我们需要沿着树向上移动,直至找到根节点。
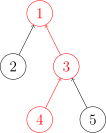
代码实现
1 | size_t dsu::find(size_t x) { return pa[x] == x ? x : find(pa[x]); } |
路径压缩
查询过程中经过的每个元素都属于该集合,我们可以将其直接连到根节点以加快后续查询。
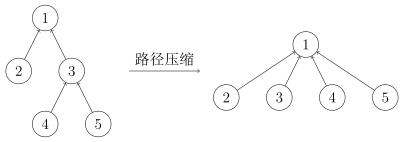
代码实现
1 | size_t dsu::find(size_t x) { return pa[x] == x ? x : pa[x] = find(pa[x]); } |
合并
要合并两棵树,我们只需要将一棵树的根节点连到另一棵树的根节点。
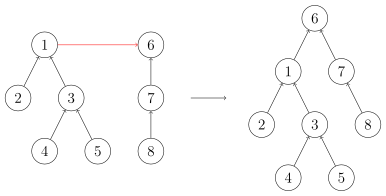
代码实现
1 | void dsu::unite(size_t x, size_t y) { pa[find(x)] = find(y); } |
启发式合并
合并时,选择哪棵树的根节点作为新树的根节点会影响未来操作的复杂度。我们可以将节点较少或深度较小的树连到另一棵,以免发生退化。
由于需要我们支持的只有集合的合并、查询操作,当我们需要将两个集合合二为一时,无论将哪一个集合连接到另一个集合的下面,都能得到正确的结果。但不同的连接方法存在时间复杂度的差异。具体来说,如果我们将一棵点数与深度都较小的集合树连接到一棵更大的集合树下,显然相比于另一种连接方案,接下来执行查找操作的用时更小(也会带来更优的最坏时间复杂度)。
当然,我们不总能遇到恰好如上所述的集合——点数与深度都更小。鉴于点数与深度这两个特征都很容易维护,我们常常从中择一,作为估价函数。而无论选择哪一个,时间复杂度都为
,具体的证明可参见 References 中引用的论文。 在算法竞赛的实际代码中,即便不使用启发式合并,代码也往往能够在规定时间内完成任务。在 Tarjan 的论文中,证明了不使用启发式合并、只使用路径压缩的最坏时间复杂度是
。在姚期智的论文中,证明了不使用启发式合并、只使用路径压缩,在平均情况下,时间复杂度依然是 。 如果只使用启发式合并,而不使用路径压缩,时间复杂度为
。由于路径压缩单次合并可能造成大量修改,有时路径压缩并不适合使用。例如,在可持久化并查集、线段树分治 + 并查集中,一般使用只启发式合并的并查集。
按照结点数合并的参考实现:
1 | struct dsu { |
删除
要删除一个叶子节点,我们可以将其父亲设为自己。为了数据结构的鲁棒性,要保证删除的元素都是叶子,我们可以预先为每个节点制作副本,并将其副本作为父亲。
代码实现:
1 | struct dsu { |
移动
与删除类似,通过以副本作为父亲,保证要移动的元素都是叶子。
代码实现:
1 | void dsu::move(size_t x, size_t y) { |
复杂度
时间复杂度
同时使用路径压缩和启发式合并之后,并查集的每个操作平均时间仅为
Ackermann 函数
而反 Ackermann 函数
空间复杂度
显然为
带权并查集
我们还可以在并查集的边上定义某种权值、以及这种权值在路径压缩时产生的运算,从而解决更多的问题。比如对于经典的「NOI2001」食物链,我们可以在边权上维护模 3 意义下的加法群。
可供参考的习题
References
- Tarjan, R. E., & Van Leeuwen, J. (1984). Worst-case analysis of set union algorithms. Journal of the ACM (JACM), 31(2), 245-281.ResearchGate PDF
- Yao, A. C. (1985). On the expected performance of path compression algorithms.SIAM Journal on Computing, 14(1), 129-133.
- 是否在并查集中真的有二分路径压缩优化?