视觉SLAM十四讲读书笔记:Ch06非线性优化
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第六章“非线性优化”的内容。
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第六章“非线性优化”的内容。
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第五章“相机与图像”的内容。
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第四章“李群与李代数”的章末习题
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第四章“李群与李代数”中有关李代数求导、扰动模型等的内容
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第四章“李群与李代数”中有关李群和李代数的定义、转换等基础知识的内容
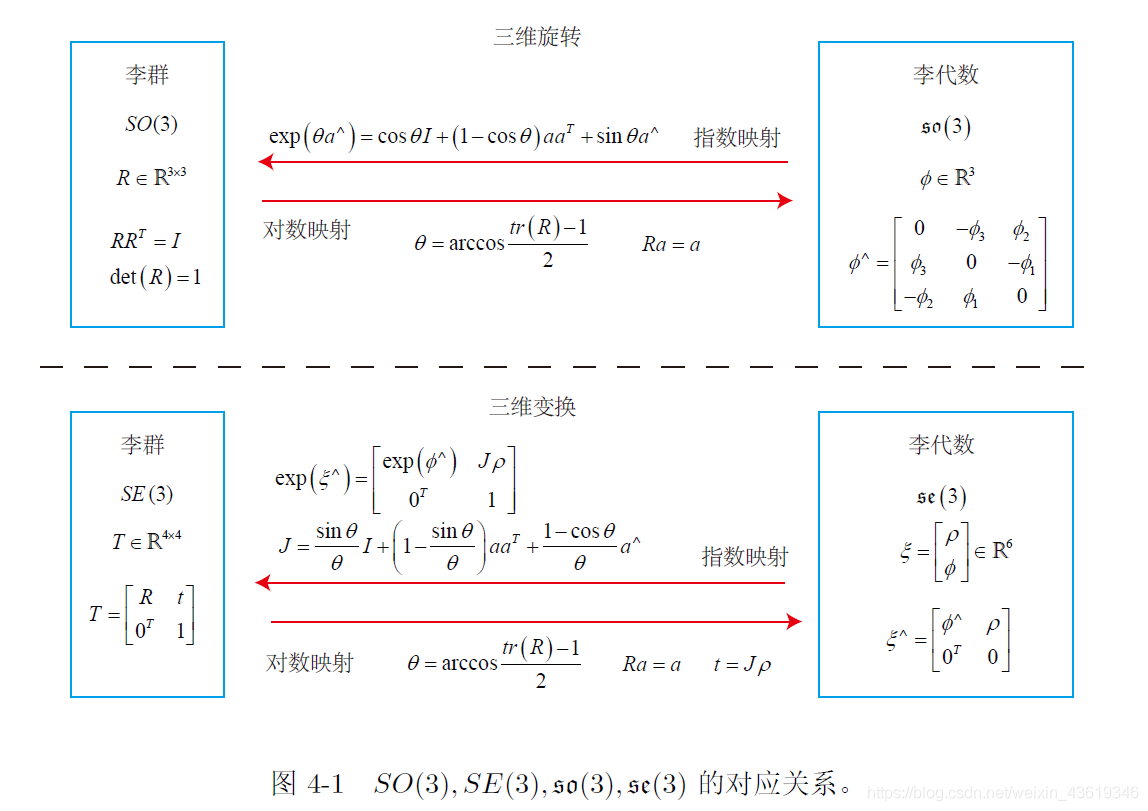
这是我系列博客《视觉SLAM十四讲》的读书笔记中的一篇,总结了第三章“三维空间刚体运动”相关的内容
主题: Vision-Language Pretraining (VLP) 学习总结:技术脉络、模型对比与未来展望 参考资料:
论文标题: FLAVA: A Foundational Language And Vision Alignment Model
作者: Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, et al.
论文链接: arXiv:2112.04482
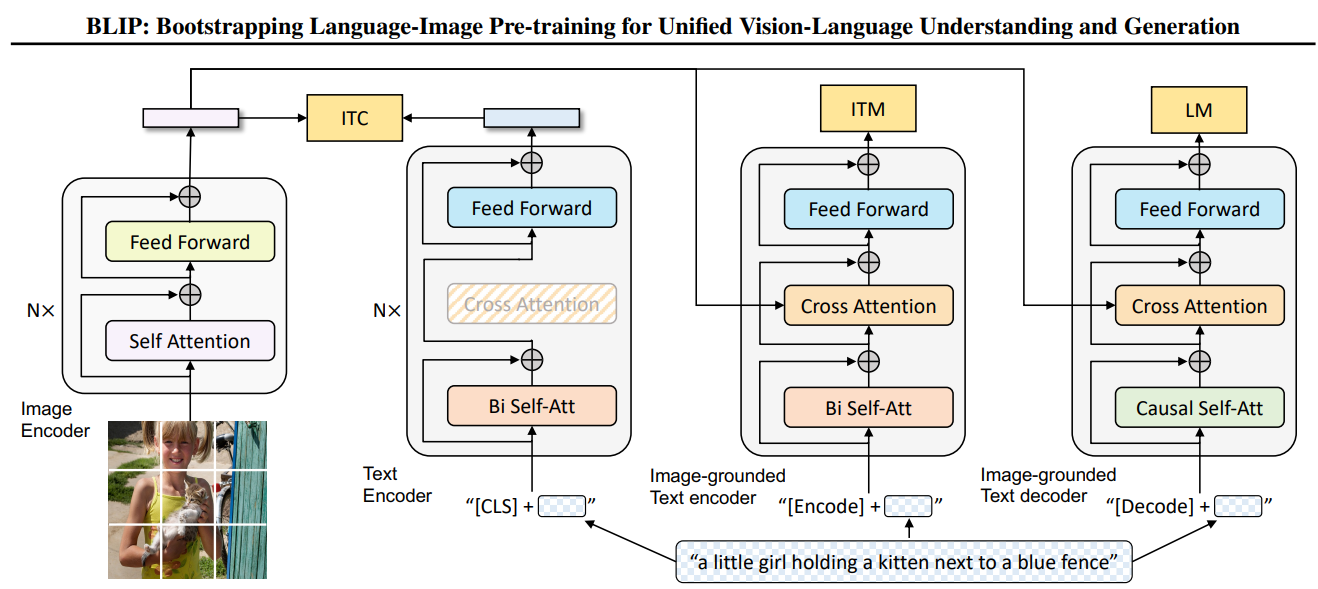
论文标题: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 作者: Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi (Salesforce Research) 论文链接: arXiv:2201.12086
本文记录了我在 MiniViLT 项目 中,从零开始实现轻量级 ViLT(Vision-and-Language Transformer)的过程。 项目目标是:在 8GB 显存环境下,独立实现并训练一个小型多模态模型,支持图文匹配任务(ITM)。